
Filer og CSV
Skrive til og lese fra fil
Vi kan åpne en fil ved å bruke syntaksen with ... as ... sammen med funksjonen open. Denne funksjonen tar inn et filnavn/sti til en fil samt en modus og returnerer et «filobjekt». Filobjektet kan vi bruke for å lese fra eller skrive til filen. For å skrive til filen bruker vi metoden write på filobjektet, mens for å lese fra filen bruker vi metoden read på filobjektet.
# Skrive til en fil
with open('minfil.txt', 'w', encoding='utf-8') as filobjekt:
filobjekt.write('Hei, verden!')
# Lese fra en fil
with open('minfil.txt', 'r', encoding='utf-8') as filobjekt:
innhold = filobjekt.read()
print(innhold) # Skriver ut 'Hei, verden!'
Noen vanlige moduser for filobjektet er:
'r': åpner filen for lesing (read)'w': åpner filen for skriving (write). Hvis filen ikke eksisterer, opprettes den. Hvis filen eksisterer, overskrives den.'a': åpner filen for skriving (append). Hvis filen ikke eksisterer, opprettes den. Hvis filen eksisterer, legges det nye innholdet til på slutten av filen.'x': åpner filen for skriving (exclusive). Hvis filen ikke eksisterer, opprettes den. Hvis filen eksisterer fra før, krasjer programmet.
I tillegg kan vi spesifisere om filen skal åpnes i tekstmodus eller binærmodus ved å legge til
't'eller'b'i modus-strengen. For eksempel'wt'eller'wb'.
't': åpner filen i tekstmodus (text). Dette er standard, og trenger derfor egentlig ikke å spesifiseres. Benytt denne modusen hvis du skal lese eller skrive tekst, som f. eks. .txt, .csv, .json, .html, .xml, .py etc.'b': åpner filen i binærmodus (binary). Dette er nødvendig hvis du skal lese eller skrive binære filer (f. eks. bilder, lyd, video, etc.). Vi vil ikke bruke denne modusen i dette emnet.
Den navngitte parameteren encoding= bør alltid spesifiseres, ellers kan du få problemer når programmet kjøres på et annet operativsystem. Dersom du skriver til en fil, bør du alltid spesifisere encoding='utf-8'. Dersom du leser fra en fil, må du benytte samme koding som ble brukt da filen ble skrevet. Les mer i kursnotater om unicode.
Hjelp, filen blir ikke funnet
Når du kjører et Python-program, kjører programmet «i» en mappe som kalles current working directory (cwd). Du kan se hvilken mappe dette er med koden:
import os
cwd = os.getcwd()
print(cwd)
Denne mappen blir bestemt av programmet som starter python. F. eks. hvis du bruker VSCode for å starte python, vil terminalen være i den samme mappen som VSCode er åpnet i (den som er nevnt med STORBOKSTAVER i filutforskeren til venstre). Cwd har altså ikke noen sammenheng med hvilken mappe filen som kjøres ligger i.
Når python får beskjed om å åpne en fil, vil den tolke filstien som blir oppgitt relativt til cwd. For eksempel, hvis filstien er kun et filnavn, antas det at filen ligger i cwd.
La oss si at vi har følgende filstruktur:
topfolder/
foo.txt
subfolder/
myscript.py
qux.txt
I skriptet myscript.py har vi følgende kode:
with open('bar.txt', 'w', encoding='utf-8') as f:
print(f.write('Hello from bar.txt!'))
Hvor vil da filen bar.txt bli opprettet? Svaret er: det kommer an på.
- Hvis du kjører myscript.py fra topfolder (altså hvis cwd er topfolder), vil filen bar.txt bli opprettet i topfolder.
- Hvis du kjører myscript.py fra subfolder (altså hvis cwd er subfolder), vil filen bar.txt bli opprettet i subfolder.
Dersom du kjører programmet fra VSCode, vil cwd være den mappen du har åpnet VSCode i. Hvis vi har åpnet VSCode i topfolder, ser filutforskeren i VSCode slik ut:
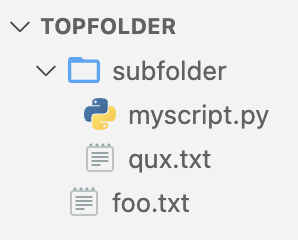
Da filen bar.txt vil da bli opprettet mappen topfolder – til tross for at kildekoden befinner seg i mappen subfolder.
La oss si at vi har følgende filstruktur:
inf100/
lab5/
lab6/
lab7/
check_valid_word.py
wordlist.txt
I skriptet check_valid_word.py har vi følgende kode:
with open('wordlist.txt', 'r', encoding='utf-8') as f:
content = f.read()
...
Programmet krasjer med følgende feilmelding:
File "/your/path/to/inf100/lab7/findword.py", line 1, in <module>
with open('wordlist.txt', 'r', encoding='utf-8') as f:
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
FileNotFoundError: [Errno 2] No such file or directory: 'wordlist.txt'
Hva er feilen? Svaret er sannsynligvis: du kjører programmet fra feil mappe (cwd er altså ikke /path/to/inf100/lab7). Kan det for eksempel være at du kjører programmet fra inf100 -mappen?
Feilsøkingssteg:
-
Sjekk hva cwd er ved å legge til følgende linjer i programmet:
import osogprint(os.getcwd()) -
Hvis cwd ikke er /your/path/to/inf100/lab7: åpne VSCode i lab7 -mappen (File -> Open Folder -> velg lab7 -mappen) og kjør programmet nå.
-
Alternativt kan du navigere til lab7 -mappen med kommandoer i terminalen og kjøre programmet derfra.
Det er mulig å programmatisk endre cwd til å bli samme mappe som filen som kjøres ligger i:
import os
directory_of_current_file = os.path.dirname(__file__)
os.chdir(directory_of_current_file) # endrer cwd
Dette kan kanskje gjøre ting lettere i utviklingsfasen og for raske og enkle formål, men er sannsynligvis ikke noe en erfaren programmerer ville ønsket seg, siden man da må flytte hele programmet hvis man vil bruke det i en annen mappe.
Enkel CSV -håndtering
En CSV-fil er en tekstfil som inneholder tabell-data. CSV står for «comma separated values», og det er nettopp det det er: en tekstfil hvor hver linje inneholder en rekke verdier som er separert med komma (eller et annet symbol). Hver linje i filen representerer en rad i tabellen, og hver verdi representerer en kolonne i tabellen.
Regneark i Microsoft Excel eller Google Sheets kan lagres som CSV-filer. Dette er et vanlig format for å utveksle data mellom ulike programmer.
Innholdet i en CSV-fil (people.csv) kan se slik ut:
Navn,Alder,Høyde
Ola,20,1.80
Kari,19,1.65
Per,21,1.73
Oda,20,1.74
Det finnes biblioteker i Python som er spesielt laget for å lese CSV-filer, men i dette avsnittet skal vi vise hvordan vi kan lese dem helt selv. En csv-fil er nemlig bare en tekstfil, og vi kan lese den på akkurat samme måte som vi leser andre tekstfiler.
###########################################
### LESE INPUT OG OPPRETTE DATASTRUKTUR ###
###########################################
with open('people.csv', 'r', encoding='utf-8') as file_object:
# content_string er streng som inneholder hele innholdet i filen
content_string = file_object.read()
# .strip fjerner whitespace på begynnelsen og slutten av strengen
content_string = content_string.strip()
# .split('\n') klipper opp strengen ved linjeskift, og gir oss en
# liste med bitene som er igjen
content_lines = content_string.split('\n')
# Vi oppretter en 2D-liste (en liste av lister) som skal inneholde
# tabellen vår
table = []
for line in content_lines:
# .split(',') klipper opp strengen ved komma, og gir oss en
# liste med bitene som er igjen
values = line.split(',')
table.append(values)
# Vi kan nå aksessere enkeltverdier i tabellen vår ved å bruke
# indeksering på samme måte som vi gjør med andre lister
print(table[0][1]) # Alder
print(table[1][0]) # Ola
print(table[3][2]) # 1.73
# Ofte gir det mening å ha overskriftene og selve dataene i separate
# variabler.
headers = table[0] # første rad
data = table[1:] # alle rader unntatt den første
##############################################
### UTFØR SELVE DATABEHANDLINGEN VI ØNSKER ###
##############################################
# Et år har passert! Øk alle aldre med 1 i datasettet.
for row in data:
row[1] = 1 + int(row[1]) # PS: dette endrer typen til int
############################
### PRESENTER RESULTATET ###
############################
# Skriv den endrede tabellen til en ny fil
with open('people_a_year_later.csv', 'w', encoding='utf-8') as file_object:
for row in table:
# Konverterer alle cellene i listen til strenger
string_row = [str(x) for x in row]
# .join() limer sammen strenger i en liste til én stor streng
# med den gitte limestrengen mellom hver av dem
line = ','.join(string_row)
file_object.write(line + '\n')