
Eksamen
| 27. november 2023 |
| 4 timer |
| Lukket digital eksamen (med safe exam browser). |
| Alle skrevne og trykte hjelpemidler tillatt. |
Oppgavetekster, løsningsforslag og sensorveiledning finner du på denne siden.
Fordi eksamen var en lukket digital eksamen uten tilgang til å kjøre koden eller bruke internett, bes sensor ikke gi poengtrekk for forhold som enkelt ville blitt oppdaget og raskt rettet ved kjøring av koden. Dette inkluderer blant annet:
- manglende
import-setninger, - manglende kodeord (som f. eks. manglende
defforan funksjonsdefinisjoner), - feil navn på funksjoner og metoder i standardbiblioteket, i egen kode eller i eksterne moduler (såfremt det fremgår noenlunde av funksjonsnavnet hva kandidaten egentlig mener),
- feil navn på variabler (f. eks. kalle den samme variabelen både
totalogsumi ulike deler av koden), - enkle syntaks-feil (f. eks. manglende kolon etter
if-setninger), - og så videre.
Logiske feil skal det likevel (som hovedregel) bli trukket litt for; selv om man kunne ha oppdaget at noe var feil ved kjøring av koden. Dette inkluderer blant annet:
-
presedensfeil,
-
forveksling av indekser og elementer,
-
off-by-one -feil,
-
feil i algoritmer,
-
og så videre.
1 Automatisk rettet
- For å lese oppgavene uten fasit, se oppgavesettet over.
- Fasit for automatisk rettede oppgaver: pdf
2 Forklaring
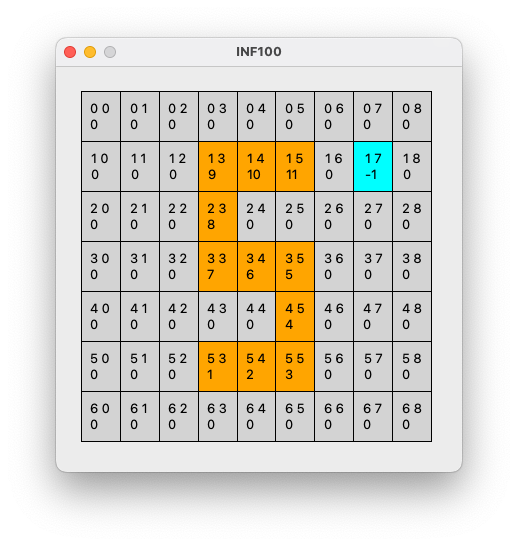
Tidemann held på med lab6 (Snake), men har gjort noko feil i steget der han skal teikna eit rutenett. Når test-programmet hans view_test.py køyrer, blir programmet til venstre vist, sjølv om han eigentleg skulle ønske at det såg ut som programmet til høgre. Det kjem ingen feilmeldingar i terminalen.

|
|
Kva har Tidemann gjort feil? Les koden hans, og forklar:
- kva han har gjort feil,
- kvifor feilen fører til åtferda som blir vist, og
- kva han kan gjera for å retta feila.
Maks 400 ord.
Tidemann har gjort flere feil:
-
I snake_view.py på linje 11 i funksjonen draw_board er det oppgitt at løkken skal gå gjennom elementene i
range(rows). Dette fører til at det blir tegnet for få kolonner i rutenettet. For å rette feilen, endre linje 11 slik at løkken går igjennom elementene irange(cols)i stedet. -
I snake_view.py, på linje 32-33 i funksjonen get_color angis det at fargen skal være oransje dersom den innkommende verdien er større enn eller lik 0. Dette fører til at funksjonen vil returnere fargen oransje selv om verdien er
0, som ikke er riktig oppførsel, og vi ser på bildet at hele brettet tegnes i den oransje fargen, også der det skulle vært grå. Dette problemet kan løses på (minst) tre ulike måter, og ideelt sett burde man gjøre alle disse rettelsene (selv om hvert enkelt grep i seg selv er egentlig er tilstrekkelig for rette funksjonaliteten):- I stedet for å sammenligne med
>=, burde man sammenlignet med>. Da ville ikke kroppen til denne if-setningen bli utført, og det er istedet den lysegrå fargen som blir angitt til color-variabelen tidligere i funksjonen (linje 30-31) som gjør seg gjeldende. - I stedet for å angi verdi til en variabel
colorsom returneres på slutten av funksjonen, kunne man returnert verdier direkte inne i if-blokkene. Da ville funksjonen returnert allerede i den første if-blokken. - I stedet for å benytte flere if-setninger, burde man benyttet seg av én if-setning med flere elif-ledd; altså endre
ifpå linje 32 tilelif. Da ville color-variabelen blitt angitt kun i det første leddet av if-elif-sekvensen.
- I stedet for å sammenligne med
- I snake_view.py, på linje 22-26 i funksjonen draw_board tegnes debug-informasjon for en celle i en if-setning; men denne if-setningen har et innrykk for lite, og utføres derfor kun én gang for hver rad, etter at den innerste løkken er ferdig utført. Variablene x_left, x_right, y_top og y_bottom vil fortsatt ha de verdiene de fikk i siste iterasjon av den innerste løkken, som er ansvarlig for å tegne siste kolonne i raden. Derfor tegnes debug-informasjonen kun for den siste kolonne. For å rette koden, må innrykket på linjene 22-26 økes med ett innrykk (fire mellomrom).
- For få kolonner (2 poeng)
- Identifiserer at dette er et problem.
- Foreslår funksjonell løsning for hva som kan gjøres for å rette problemet.
- For mye oransje (2 poeng)
- Identifiserer at dette er et problem.
- Foreslår funksjonell løsning for hva som kan gjøres for å rette problemet.
- Debug vises kun for siste kolonne (2 poeng)
- Identifiserer at dette er et problem.
- Foreslår funksjonell løsning for hva som kan gjøres for å rette problemet.
- Helhetsvurdering (4 poeng)
- Meningsfulle forklaringer av sammenheng mellom kode og resultatbilde.
- Gode bruk av faguttrykk.
- Finner ikke feil som ikke er feil.
Othilie har lese seg opp om mengder og oppslagsverk, og har lagt merke til at dei er muterbare. Men kva innberar eigentleg det? Kva omsyn må Othilie ta med muterbare verdiar, som kanskje ikkje ville vore nødvendig elles?
Gi ei forklaring til Othilie med illustrerande døme. Me forventar ca 3-4 avsnitt, ikkje meir enn 600 ord.
En verdi er muterbar hvis det er mulig å endre på selve verdien i minnet etter at den har blitt opprettet første gang. Når Othilie arbeider med muterbare verdier, må hun være oppmerksom på at endringer i verdien vil påvirke alle referanser (aliaser) til den verdien. Dette kan føre til uventede bugs hvis én del av kildekoden tror det er greit å mutere verdien, mens en annen del av kildekoden ikke er klar over at verdien muteres.
Et eksempel: anta at Othilie har et oppslagsverk som inneholder karakterkortet hennes:
othilie_grades = {'Skriving': 5, 'Lesing': 4 }
Othilie lurer på hva snittkarakteren hennes blir hvis hun får karakteren x i sitt neste fag. Hun skriver derfor følgende funksjon:
def ave_if_adding_grade_x(grades, x):
grades['new_grade'] = x
# OBS! operasjonen over muterer grades!
# men det er i det minste lett å regne ut gjennomsnittet nå:
return sum(grades.values()) / len(grades)
Når Othilie tester funksjonen, ser det ut som den fungerer som den skal:
print('Testing ave_if_adding_grade_x...', end=' ')
assert 5.0 == ave_if_adding_grade_x(othilie_grades, 6)
assert 4.0 == ave_if_adding_grade_x(othilie_grades, 3)
print('OK') # Tjohei, testene passerer!
Men når Othilie nå ser på karakterkortet sitt, ser hun at det har skjedd noe rart:
print(othilie_grades)
Gir utskriften
{'Skriving': 5, 'Lesing': 4, 'new_grade': 3}
Det som har skjedd, er at funksjonen ave_if_adding_grade_x muterer grades slik at det blir enklere å deretter regne ut gjennomsnittet. Det man ikke tenkte på, var at grades i ave_if_adding_grade_x er et alias til othilie_grades i hovedprogrammet, slik at enhver mutasjon av grades også vil reflekteres i othilie_grades.
Generelt når man benytter seg av verdier som er av en muterbar type, må man være bevisst på hvorvidt det finnes andre referanser/aliaser til verdien og hvilken rolle den spiller der før man bestemmer seg for å mutere den.
- 2 poeng: meningsfull definisjon («En verdi er muterbar dersom selve objektet kan endres uten å opprette en ny verdi i minnet») eller lignende.
- 2 poeng: meningsfullt svar på hvilke hensyn man må ta («Man må være bevisst på hvorvidt det finnes andre referanser/aliaser til en verdi før man bestemmer seg for å mutere den») eller lignende.
- 2 poeng: eksempel basert på mengder eller oppslagsverk, ikke kun lister.
- 2 poeng: meningsfull drøfting av aliaser/to variabler som peker til samme objekt, eventuelt et godt eksempel som illustrerer dette.
- 2 poeng: helhetsvurdering (bruk av fagbegreper, påstander gir mening, forståelse er korrekt etc).
3 Kodeskriving
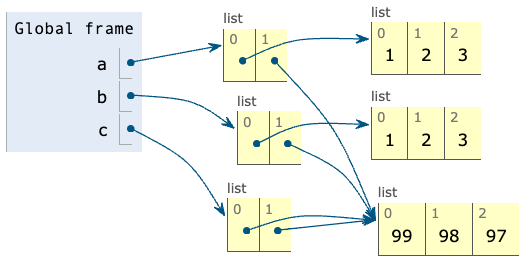
Skriv en kodesnutt slik at variabler og minnets tilstand for variablene a, b og c blir som vist over.
Klikk på «se steg» -knappen for å verifisere at denne koden gir riktig bilde av minnet.
a = [[1, 2, 3], [99, 98, 97]]
b = [[1, 2, 3], a[1]]
c = [a[1], a[1]]
- 1 poeng hvis
aer korrekt (a == [[1, 2, 3], [99, 98, 97]]). - 1 poeng hvis
b[0]er korrekt og peker på en annen liste enna[0]. - 1 poeng hvis
b[1]peker på samme liste soma[1]. - 1 poeng hvis
cer korrekt (bådec[0]ogc[1]peker på samme objekt soma[1]).
Sensor har anledning til å gjøre en skjønnsmessig justering i tilfeller der det er gjort feil disse testene ikke tar høyde for. Poengsummen som beskrevet over kan regnes ut med følgende kode:
points = sum([
a == [[1, 2, 3], [99, 98, 97]],
(b[0] == [1, 2, 3]) and (b[0] is not a[0]),
b[1] is a[1],
c[0] is c[1] is a[1],
])
# PS: sum av en liste med boolske verdier gir antall True-verdier i listen.
Anta at months_of_temps er en variabel som peker på en to-dimensjonal liste av flyttall. De indre listene inneholder flyttall som representerer gjennomsnittstemperaturen for hver dag i en måned; mens den ytterste listen inneholder flere ulike måneder. Forskjellige måneder kan ha ulikt antall dager.
Skriv en funksjon average_temp med en parameter months_of_temps som beskrevet over. La funksjonen returnere gjennomsnittstemperaturen for alle dagene, uansett måned.
Eksempel på months_of_temps:
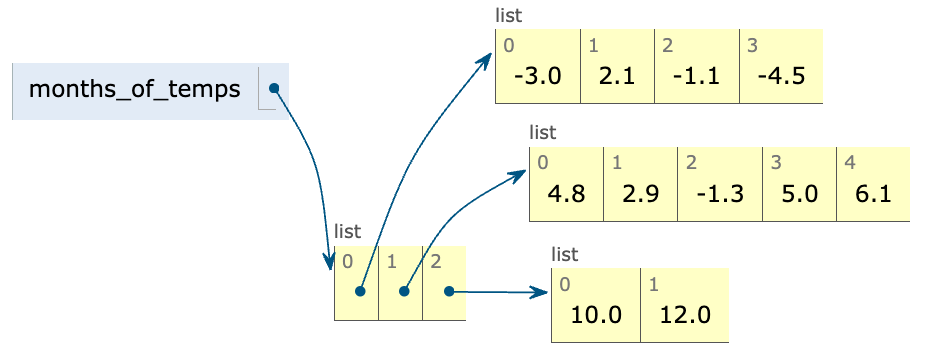
Hvis funksjonen du skriver kalles med eksempelet vist over som argument, skal returverdien bli 3.0: i eksempelet er det 11 ulike måleverdier (dager med temperaturmålinger), og summen av alle måleverdiene er 33.0.
Hint:
- tell hvor mange måleverdier som finnes,
- regn ut den totale summen av alle måleverdiene, og
- returner den totale summen delt på antall måleverdier.
Sensor vil vektlegge:
- Forståelse av løkker. Ikke bland indekser med verdier.
- Forståelse av funksjoner.
- Helhetlig algoritmisk forståelse.
# Løsningsforslag
def average_temp(months_of_temps):
count = 0
total = 0
for month in months_of_temps:
for temp in month:
count += 1
total += temp
return total / count
# Kjør denne koden for å verifisere at løsningsforslaget fungerer:
print('Testing average_temp...', end=' ')
assert 3.0 == average_temp([
[-3.0, 2.1, -1.1, -4.5],
[4.8, 2.9, -1.3, 5.0, 6.1],
[10.0, 12.0],
])
print('OK')
Alternative løsninger
def average_temp(months_of_temps):
count = 0
total = 0
for month in months_of_temps:
count += len(month)
total += sum(month)
return total / count
def average_temp(months_of_temps):
count = sum([len(month) for month in months_of_temps])
total = sum([sum(month) for month in months_of_temps])
return total / count
- 2 poeng: løkke som itererer over alle måneder.
- 2 poeng: summerer alle måleverdiene på en korrekt måte.
- 2 poeng: teller antall måleverdier på en korrekt måte.
- 1 poeng: bruker riktig formel for å regne ut gjennomsnitt (totalsum / antall).
- 1 poeng: helhetsvurdering.
En liste med tall kalles geometrisk hvis det finnes en konstant k, kalt kvotienten, slik at hvert tall, bortsett fra det første, er lik det foregående tallet multiplisert med k. For eksempel er [3, 6, 12] en geometrisk liste med kvotient 2.
Forenklinger og antakelser for denne oppgaven:
- Geometriske lister med kvotient 0 er gørrkjedelige. En slik geometrisk liste består av kun 0’er, bortsett fra (kanskje) det første tallet. For enkelhets skyld definerer vi enhver liste som inneholder tallet 0 til å ikke være geometrisk.
- For enkelhets skyld sier vi også at en liste med færre enn to elementer er geometrisk med kvotient 1 (såfremt den ikke inneholder 0).
Denne oppgaven består av fire deloppgaver (i), (ii), (iii), og (iv). Når du løser en gitt deloppgave kan du anta at alle funksjonen du skulle skrevet i de tidligere deloppgavene er korrekt implementert – du står f. eks. fritt til å bruke funksjonen i oppgave (ii) som en hjelpefunksjon i oppgave (iii) selv om du ikke faktisk løste oppgave (ii).
Oppgave (i)
Skriv en funksjon get_geometric_quotient(a) som avgjør om en liste a med tall er geometrisk eller ikke. Hvis listen er geometrisk, returneres kvotienten. Hvis listen ikke er geometrisk, returneres None.
# Test 1
actual = get_geometric_quotient([3, 6, 12])
expected = 2
assert expected == actual
# Test 2
actual = get_geometric_quotient([4, 8, 8, 16, 3, 9, 27, 32])
expected = None
assert expected is actual
# Test 3
actual = get_geometric_quotient([42])
expected = 1
assert expected == actual
Oppgave (ii)
En subliste er en liste som består av en sammenhengende del av en annen liste. For eksempel:
[8, 8, 16]er en subliste av[4, 8, 8, 16, 4].[4, 8, 16]er ikke en subliste av[4, 8, 8, 16, 4], fordi den ikke er sammenhengende/er ikke i samme rekkefølge.
Skriv en funksjon len_geometric_sublist_starting_at(a, start_i) som finner lengden til den lengste sublisten av a som starter på indeks start_i og som også er geometrisk.
a = [4, 8, 8, 16, 3, 9, 27, 81, 32]
# Test 1: fra i=2, er lengste subliste 8, 16 med k = 2, har lengden 2
actual = len_geometric_sublist_starting_at(a, 2)
expected = 2
assert expected == actual
# Test 2: fra i=3, er lengste subliste 16, 3 med k = 0.1875, har lengden 2
actual = len_geometric_sublist_starting_at(a, 3)
expected = 2
assert expected == actual
# Test 3: fra i=4, er lengste subliste 3, 9, 27, 81 med k = 3, har lengden 4
actual = len_geometric_sublist_starting_at(a, 4)
expected = 4
assert expected == actual
Oppgave (iii)
Skriv en funksjon longest_geometric_sublist(a) som returnerer den lengste sublisten av a som også er geometrisk. Dersom det er flere enn én delliste med denne lengden, returneres den tidligste av dem.
# Test
a = [4, 8, 8, 16, 3, 9, 27, 32]
actual = longest_geometric_sublist(a)
expected = [3, 9, 27]
assert expected == actual
Oppgave (iv)
Denne deloppgaven er en utfordring for dem som sikter på en A i emnet. Du bør spare denne til slutt, og løse de andre oppgavene på eksamen først.
I denne deloppgaven kan du ikke bruke modulen itertools om du vil ha full score. Om du likevel benytter den, kan du maksimalt få 40% av poengene.
En subsekvens er en liste som består av en del av elementene i en annen liste, der elementene i subsekvensen opptrer i samme rekkefølge som i den opprinnelige listen. For eksempel:
[4, 16, 64]er en subsekvens av[4, 8, 8, 16, 64].[4, 64, 16]er ikke en subsekvens av[4, 8, 8, 16, 64], fordi elementene ikke kommer i samme rekkfølge.
En subsekvens må ikke nødvendigvis være sammenhengende i den opprinnelige listen, men elementene må opptre i samme rekkefølge.
Skriv en funksjon longest_geometric_subsequence(a) som returnerer den lengste subsekvensen av a som også er geometrisk. Dersom det er flere enn én subsekvens med denne lengden, skal du returnere den tidligste av dem.
# Test
a = [4, 8, 8, 16, 64, 3, 9, 27, 32]
actual = longest_geometric_subsequence(a)
expected = [4, 8, 16, 32]
assert expected == actual
Hint:
- Begynn med å prøve alle muligheter for valg av de første to elementene i subsekvensen.
Merk:
- Sensor retter først og fremst for korrekthet, ikke for effektivitet; men svært klumsete løsninger kan likevel bli trukket litt.
# (i)
def get_geometric_quotient(a):
if 0 in a:
return None
if len(a) < 2:
return 1
k = a[1] / a[0]
for i in range(len(a) - 1):
if not almost_equals(a[i + 1]/a[i], k):
return None
return k
def almost_equals(a, b):
return abs(a - b) < 0.0000000001
# (ii)
def len_geometric_sublist_starting_at(a, start_i):
# Steg 1: finn alle potensielle løsninger som begynner i start_i
potential_sublists = []
for end_i in range(start_i, len(a) + 1):
sublist = a[start_i:end_i]
potential_sublists.append(sublist)
# Steg 2: finn lengdene for de løsningene som faktisk er geometriske
valid_sublist_lengths = []
for sublist in potential_sublists:
if get_geometric_quotient(sublist) is not None:
valid_sublist_lengths.append(len(sublist))
# Steg 3: finn lengste løsning
return max(valid_sublist_lengths)
# (iii)
def longest_geometric_sublist(a):
# Steg 1: finn lengdene til alle sublister som starter i alle
# mulige start-indekser
lengths = []
for start_i in range(len(a)):
length = len_geometric_sublist_starting_at(a, start_i)
lengths.append(length)
# Steg 2: finn start-indeks til lengste lengde
best_start_i = 0
for i in range(len(a)):
if lengths[i] > lengths[best_start_i]:
best_start_i = i
# Steg 3: returner lengste subliste
end_i = best_start_i + lengths[best_start_i]
return a[best_start_i:end_i]
# (iv)
def longest_geometric_subsequence(a):
if len(a) < 2:
return a
best_subsequence = []
for first_i in range(len(a)):
for second_i in range(first_i + 1, len(a)):
candidate = longest_gs_with_first_points_at(a, first_i, second_i)
if len(candidate) > len(best_subsequence):
best_subsequence = candidate
return best_subsequence
def longest_gs_with_first_points_at(a, first_i, second_i):
first_value = a[first_i]
second_value = a[second_i]
k = second_value / first_value
result = [first_value, second_value]
latest_i = get_next_i(a, k, second_i)
while latest_i is not None:
latest_value = a[latest_i]
result.append(latest_value)
latest_i = get_next_i(a, k, latest_i)
return result
def get_next_i(a, k, previous_i):
previous_val = a[previous_i]
target_value = k * previous_val
for i in range(previous_i + 1, len(a)):
if almost_equals(target_value, a[i]):
return i
return None
###############
### Testing ###
###############
print('Testing (i)...', end=' ')
# Test 1
actual = get_geometric_quotient([3, 6, 12])
expected = 2
assert expected == actual
# Test 2
actual = get_geometric_quotient([4, 8, 8, 16, 3, 9, 27, 32])
expected = None
assert expected is actual
# Test 3
actual = get_geometric_quotient([42])
expected = 1
assert expected == actual
print('OK')
print('Testing (ii)...', end=' ')
a = [4, 8, 8, 16, 3, 9, 27, 81, 32]
# Test 1: fra i=2, er lengste sublist 8, 16 med k = 2 (og lengde 2)
actual = len_geometric_sublist_starting_at(a, 2)
expected = 2
assert expected == actual
# Test 2: fra i=3, er lengste sekvensen 16, 3 med k = 0.1875 (og lengde 2)
actual = len_geometric_sublist_starting_at(a, 3)
expected = 2
assert expected == actual
# Test 3: fra i=4, er lengste sekvensen 3, 9, 27, 81 med k = 3 (og lengde 4)
actual = len_geometric_sublist_starting_at(a, 4)
expected = 4
assert expected == actual
# Test 4: fra i=6, er lengste sekvensen 27, 32 med k = 32/81 (og lengde 2)
actual = len_geometric_sublist_starting_at(a, 7)
expected = 2
assert expected == actual
# Test 4: fra i=7, er lengste sekvensen 32 med k = 1 (og lengde 1)
actual = len_geometric_sublist_starting_at(a, 8)
expected = 1
assert expected == actual
print('OK')
print('Testing (iii)...', end=' ')
a = [4, 8, 8, 16, 3, 9, 27, 32]
actual = longest_geometric_sublist(a)
expected = [3, 9, 27]
assert expected == actual
a = [4, 8, 8, 16, 3, 9, 27]
actual = longest_geometric_sublist(a)
expected = [3, 9, 27]
assert expected == actual
a = [4, 8, 16, 8, 4, 2]
actual = longest_geometric_sublist(a)
expected = [16, 8, 4, 2]
assert expected == actual
a = [2, 4, 8, 16, 8, 4, 2]
actual = longest_geometric_sublist(a)
expected = [2, 4, 8, 16]
assert expected == actual
print('OK')
print('Testing (iv)...', end=' ')
a = [4, 8, 8, 16, 64, 3, 9, 27, 32]
actual = longest_geometric_subsequence(a)
expected = [4, 8, 16, 32]
assert expected == actual
print('OK')
# For golfere: komprimert variant av løsningen over
def len_geometric_sublist_starting_at(a, start_i):
pot = [a[start_i:end_i] for end_i in range(start_i, len(a) + 1)]
return max([len(x) for x in pot if get_geometric_quotient(x) is not None])
# Variant av løsningsforslaget som
# - kombinerer steg 1 og 2 i samme løkke,
# - utnytter at lengden på sublist alltid øker, og
# - avbryter løkken så fort en sublist ikke er geometrisk.
# Fordi denne løkken avbrytes når en sublist ikke er geometrisk,
# vil den være raskere enn løsningene over.
def len_geometric_sublist_starting_at(a, start_i):
max_len = 0
for end_i in range(start_i, len(a) + 1):
my_sublist = a[start_i:end_i]
if get_geometric_quotient(my_sublist) is None:
break
else:
max_len = len(my_sublist)
return max_len
# Variant av forrige løsning, men med while-løkker, og som utnytter
# verdien av end_i når løkken avbrytes i stedet for å huske max_len
def len_geometric_sublist_starting_at(a, start_i):
end_i = start_i
while end_i <= len(a):
if get_geometric_quotient(a[start_i:end_i]) is None:
break
end_i += 1
return end_i - start_i - 1
# Komprimert variant av forrige løsning
def len_geometric_sublist_starting_at(a, start_i):
ei = start_i
while ei <= len(a) and get_geometric_quotient(a[start_i:ei]) is not None:
ei += 1
return ei - start_i - 1
# Uten bruk av hjelpefunksjon (er raskere enn å gjøre mange beskjæringer)
def len_geometric_sublist_starting_at(a, start_i):
if start_i + 1 == len(a):
return 1
k = a[start_i + 1] / a[start_i]
end_i = start_i
while end_i < len(a) - 1 and almost_equals(a[end_i + 1] / a[end_i], k):
end_i += 1
return end_i - start_i + 1
# For golfere: komprimert versjon
# (PS: lambda er ikke pensum)
def longest_geometric_sublist(a):
lens = [len_geometric_sublist_starting_at(a, i) for i in range(len(a))]
i, k = max(enumerate(lens), key=lambda x: (x[1], -x[0]))
return a[i:i + k]
# For dem som syntes lav kjøretid er viktig
def longest_geometric_sublist(a):
best_start_i = -1
best_length = -1
start_i = 0
while start_i < len(a):
length = len_geometric_sublist_starting_at(a, start_i)
if length > best_length:
best_length = length
best_start_i = start_i
start_i += max(1, length - 1)
return a[best_start_i:best_start_i + best_length]
# Løsning med itertools (maks 2 poeng)
# Merk at denne løsningen er VELDIG treg for selv moderat store lister
import itertools
def longest_geometric_subsequence(a):
best_subsequence = []
for size in range(1, len(a) + 1):
for subsequence in itertools.combinations(a, size):
if get_geometric_quotient(subsequence) is not None:
best_subsequence = subsequence
break
return list(best_subsequence)
(i) (5 poeng)
- 1 poeng: håndterer lister med lengde 0 og 1.
- 1 poeng: finner kvotienten (a[1] / a[0]).
- 1 poeng: itererer gjennom elementene i listen.
- 1 poeng: returnerer None (sannsynligvis i løkken) hvis kvotienten ikke stemmer.
- 1 poeng: helheten fungerer i sammenheng, og ingen off-by-one -feil
(ii) (5 poeng)
- 1 poeng: en løkke som begynner på start_i
- 1 poeng: identifiserer potensielle løsninger (sublister)
- 1 poeng: sjekk om en potensiell subliste er geometrisk (f. eks. ved å kalle get_geometric_quotient med en beskjært subliste som argument)
- 1 poeng: meningsfull metode for å huske/finne den beste løsningen
- 1 poeng: helheten fungerer i sammenheng
- Det trekkes ikke for off-by-one-feil i denne deloppgaven.
(iii) (5 poeng)
- 1 poeng: en løkke over mulige start-indekser (eller tilsvarende)
- 1 poeng: identifserer fornuftig utvalg av potensielle løsninger (f. eks. ved å kalle len_geometric_sublist_starting_at med en start-indeks som argument)
- 1 poeng: metode for å identifiser den beste av flere mulig løsninger
- 2 poeng: helheten fungerer i sammenheng (off-by-one -feil gir her -1)
(iv) (5 poeng)
- 2 poeng: identifisering av potensielle løsninger som nødvendigvis også inkluderer ønsket løsning.
- 2 poeng: helheten fungerer i sammenheng
- 1 poeng: lesbarhet; meningsfulle variabelnavn, deler opp problemet i egnede hjelpefunksjoner etc.
- Det trekkes ikke for off-by-one-feil i denne deloppgaven.
- Løsning med itertools får maksimalt 2 poeng.
Anta at den store Kvidoria har skrevet en ny episk roman i tekstfilen story.txt. Du jobber for forlaget, som er opptatt av et levende og variert språk. Redaktøren ber deg derfor om å lage et program som finner de 100 mest vanlige ordene i filen, samt hvor mange forekomster av disse ordene filen inneholder.
Hvilke hensyn må du ta for at løsningen skal fungere godt for redaktøren i praksis? (Du skal ikke besvare dette som et forklaringsspørsmål, men la i stedet ditt svar på dette spørsmålet avgjøre hvilken funksjonalitet du inkluderer i programmet ditt.)
Alle meningsfylte løsninger gir uttelling, men sensor vil vektlegge:
- anvendelighet for redaktøren,
- fornuftig valg av datastrukturerer, og
- hvor oversiktelig/lesbar koden er.
from collections import Counter
def print_most_common_words(filename, n):
content = read_file_contents(filename)
wordlist = get_clean_word_list(content)
word_counts = Counter(wordlist)
most_popular_words = get_most_popular_words(word_counts, n)
print(f'The {n} most used words in {filename} are')
for word, count in most_popular_words:
print(f'{word} ({count})')
def read_file_contents(filename):
with open(filename, 'rt', encoding='utf-8') as f:
content = f.read()
return content
def get_clean_word_list(content):
raw_words = content.split()
clean_words = []
for word in raw_words:
cleaned_word = clean(word)
if cleaned_word:
clean_words.append(cleaned_word)
return clean_words
def clean(word):
# Remove special characters and make the word all lowercase
word = word.lower()
cleaned_letters = []
for letter in word:
if letter in 'abcdefghijklmnopqrstuvwxyzæøå':
cleaned_letters.append(letter)
return ''.join(cleaned_letters)
def get_most_popular_words(word_count, n):
# Repeatedly remove the most popular word and add it to result list
result = [] # result list contains tuples on the form (word, count)
for _ in range(n):
most_popular_word = get_most_popular_word(word_count)
word_tuple = (most_popular_word, word_count[most_popular_word])
result.append(word_tuple)
word_count.pop(most_popular_word) # note: destructive operation
return result
def get_most_popular_word(word_count):
best_word = None
for word in word_count:
if best_word is None or word_count[word] > word_count[best_word]:
best_word = word
return best_word
if __name__ == '__main__':
print_most_common_words('story.txt', 100)
- 1 poeng: leser innhold fra fil
- 1 poeng: deler opp innholdet i ord
- 1 poeng: godt valg av datastruktur for telling av ord (dict, Counter, etc.)
- 1 poeng: teller hvert av ordene (f. eks. bruker Counter, eller en løkke over ordene og en dict)
- 2 poeng: finner de mest brukte ordene (f. eks. ved å sortere en liste av ordtupler eller å plukke ut det største ordet n ganger)
- 2 poeng: hensyn til redaktøren. Her er det flere ulike løsninger som kan gi uttelling, for eksempel rengjøring av datasettet ved å gjøre alt lowercase og fjerne spesialtegn; men også andre løsninger som hjelper redaktøren kan gi uttelling. Et annet eksempel være å fjerne ord som er så vanlige at de ikke gir mening å inkludere i en slik liste (f. eks. artikler, preposisjoner, etc.). Innsats for å gjøre programmet mer brukervennlig belønnes også.
- 2 poeng: lesbarhet av koden. Inndeling i hjelpefunksjoner. Gode variabelnavn og funksjonsnavn.
Etter en helhetsvurdering har sensor også anledning til å justere opp eller ned poengsummen etter skjønn for å ta hensyn til andre aspekter ved besvarelsen som ikke er dekket av kriteriene over.